불필요한 주소까지 모두 크롤링해서 수집하려고 접속하는지 확인해 볼 필요가 있습니다. 문서나 페이지의 정식 주소 외 나머지 주소는 검색엔진에 노출될 필요도 없고 사실 불필요한 수집입니다.
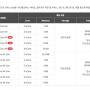
제가 운영하는 사이트에 구글,빙 에서 방문하면서 과도하게 트래픽이 발생을 해서 서버의 로그를 확인해보고 크롤링해가는 주소를 보고 불필요한 부분은 robots.txt 로 접근하지 못하도록 조치했습니다.
해외트래픽으로 10기가 이상이 발생을 하는 바람에... (구글과 빙)
User-agent: *
Disallow: /*act=IS&
Disallow: /*act=IS$
Disallow: /*search_keyword
Disallow: /*search_target
Disallow: /*listStyle=viewer
Disallow: /*act=dispBoardCategory
Disallow: /*sort_index
IS 는 통합검색의 검색에 봇들이 검색하지 못하도록 합니다. 여기서는 굉장히 많은 키워드 등으로 크롤링하게 되는데 너무 많은 과도한 크롤링이 발생합니다.
그리고 나머지는 읽어보시면 대충 어떤 상황에서 쓰이는 변수들인지 확인이 되실겁니다.
하나의 문서가 저런 형태로 수십 수백가지 패턴의 주소로 크롤링을 하게 되면 1개의 문서를 불필요하게 중복해서 수집을 시도하게 됩니다. 여기서 엄청난 트래픽이 발생하게 됩니다.
저 정도만 막아줘도 낭비되는 트래픽의 대부분을 줄일 수 있을 것으로 보입니다.
물론 사용하는 스킨이나 자료에 따라서 긁어가는 주소의 형태가 사이트마다 다 다를 수 있으니 저것 외 자신의 사이트의 access.log 를 볼 수 있다면 거이서 접근되는 주소를 시간내서 살펴보면 불필요한 패턴을 확인할 수 있습니다.